世界杯官方认证平台 AI真能学会默算? 隐式念念维链初度获取表面解释, Stuart Russell参与

裁剪|Panda
往时一年,AI推理模子的使用老本让不少开荒者叫苦。
「慢念念考」模子在处理数学、代码、逻辑题时如实推崇惊艳,但代价是每次调用都会生成几百乃至几千个「念念考token」。这些token面前谜底之前,是模子一步步演算的草稿纸。这些草稿可见,但崇高。一说念复杂数学题,光是「念念考流程」就可能浪费掉宽泛对话十倍以上的诡计资源。
念念考格式下,即使通俗雷同也费token
近期,有一些新技巧如实让东说念主们看到了压低推理老本的可能性。但无论架构如何优化,只消念念维链(Chain-of-Thought,CoT)的中间智力仍然以token体式一一生成,推理延迟就有着根人性的下限。每一步都必须在上一步完成之后才能开动,推理链有多长,恭候时辰就有多长。
这是一个结构性问题,不是工程问题。
那么,有莫得可能让模子「把草稿藏进大脑」,在不输出任何中间智力的情况下,仍然保留显式念念维链带来的推忠良力?
这恰是「隐式念念维链(ImplicitChain-of-Thought,ICoT)」想要处置的事情。而就在前些天,来自UCBerkeley和普林斯顿大学的谈判团队,在这个问题上迈出了重要一步。他们不仅给出了有打算,还在数学上严格解释了它灵验。

论文标题:TransformersProvablyLearntoInternalizeChain-of-Thought
论文地址:https://arxiv.org/abs/2605.28600v1
这项谈判的主要作家来自UC伯克利和普林斯顿大学,一作是伯克利博士生黄一笑(YixiaoHuang),率领老师包括JiantaoJiao、StuartRussell、SomayehSojoudi和SongMei。
这个团队连年来在用数学纪律领略Transformer教师机制上发表了一系列使命,涵盖从注重力格式的变成到多步推理的优化动态。这次对于ICoT的谈判,是他们将表面用具系统延长至「隐式推理」这一新规模的尝试。
念念维链的代价
要不竭这项谈判的意旨,需要先弄了了念念维链究竟贵在何处。
不错打个比喻,假如你在联结一个学生作念多位数乘法。一种纪律是让他把每一步运算都写在纸上,一排一排地算:先算诸位,再算十位,终末相加。这就是显式念念维链——每个中间律例都可见,也因此不错被锻真金不怕火和纠错。另一种纪律是让他「在脑子里算」,径直报出最终谜底。
这两种神态在信息处理上有内容远隔。前者是串行的:每一步依赖上一步的律例,无法并行。后者则否则——淌若大脑能一次性处理扫数中间诡计,谜底不错实在同期得出。
对于LLM,这个远隔径直体面前推理延迟和token浪费上。显式念念维链要求模子一一生成每个中间token,推理链有k步,就需要输出至少k个至极token,况兼这些token必须严格串行生成。对于现时起初进的推理模子,这个数字每每是几百到几千。
ICoT的想法是:能不可教师模子把中间智力「内化」到荫藏情状里,最终推理时只输出谜底,中间智力王人备不可见?
这个想法本人并不簇新。YuntianDeng等东说念主在2024年的论文《FromExplicitCoTtoImplicitCoT:LearningtoInternalizeCoTStepbyStep》就提议了一种教师纪律:先让模子学会用圆善念念维链作答,然后一步一时势把中间token「藏起来」,每次少一个,让模子从容民俗在更少的可见陈迹下完成推理。这种神态在实验中灵验,但有一个显豁错误:淌若念念维链有k步,就需要k-1个教师阶段,教师支出随推理链长度线性增长。
更根柢的问题是:莫得东说念主知说念这为什么灵验。表面上能不可保证ICoT学到的东西与显式CoT等价?在什么条目下保证?这些问题悬而未决。
中枢立异:用树状结构再行遐想教师课程
这篇论文的中枢孝顺有两个层面:一个新的教师纪律,以及针对该纪律的第一个严格数学解释。
谈判的实验平台是「k-奇偶校验」(k-parity)问题,这是一个在表面诡计机科学中经典的测试床。
给定n个比特,从中选k个,判断它们的乘积是+1如故-1。这个问题的特色是:莫得中间智力,任何有限精度的梯度下落算法,用多项式数目的样本,都无法以非世俗精度求解。但一朝提供圆善的念念维链扶助,即就是单层Transformer也能高效学会。这个对比,让它成为谈判CoT作用机制的瞎想沙盘。
重要知悉:念念维链的结构其实是一棵树。
k个比特的奇偶校验,不错明白为一棵深度为log₂k的二叉树。叶节点是原始输入比特,每个里面节点诡计其两个子节点的乘积,沿途递推到根节点获取最终谜底。这棵树的结构,2026美加墨世界杯(中国)决定了中间智力的层级干系:第一层诡计两两乘积,第二层诡计两个第一层律例的乘积,依此类推。
轨范ICoT纪律一次只藏一个token,王人备不应用这棵树的结构。而这篇论文提议的「Log-ICoT」,则一次性藏掉树的整整一层。这意味着:原本需要k-1个教师阶段,面前只需要log₂k个。对于k=16,这意味着从15个阶段缩减为4个。
24直播网2026世界杯赛事直播入口这不单是是工程上的效劳栽培。更紧迫的是,它让教师流程与模子里面的层级结构对王人——每一个Transformer层,恰好精致接收念念维链树的一个层级。
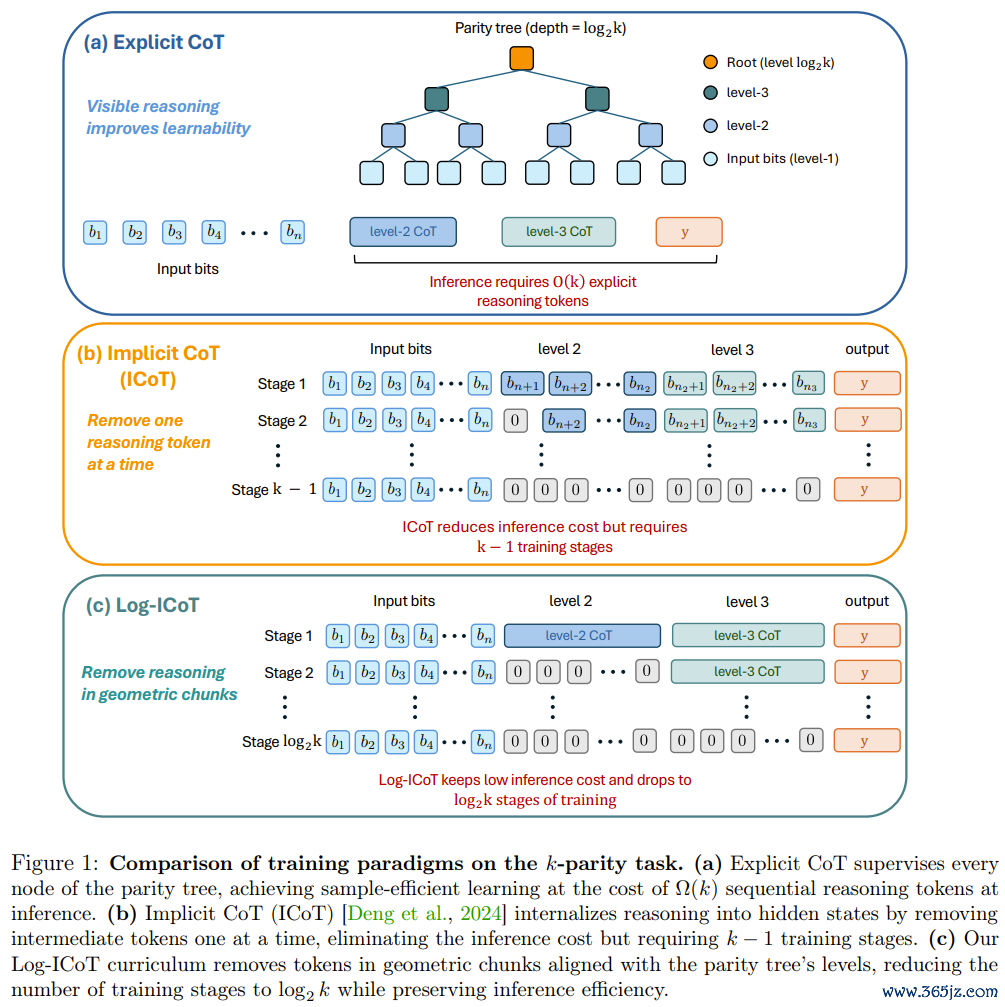
三种教师范式的对比暗示图:显式CoT、轨范ICoT、Log-ICoT
表面解释:第一次把「内化」写成定理
这项谈判最具里程碑意旨的部分,是给出了ICoT的第一个严格不断保证。
定理的中枢内容(Theorem1):一个L层Transformer,在Log-ICoT课程下教师,只需多项式数目(n^(2+ε)量级)的样本和log₂k个梯度智力,就能以接近1的概率,在测试时从纯输入比特径直展望出正确的k-奇偶校验律例——错误指数级小。

这与显式CoT的样本复杂度匹配,但推理时不需要任何中间token的输出。
解释流程濒临两个主要技巧挑战,团队分别用两种遐想技能克服:
第一个挑战是「泄露坍缩」。在多层Transformer中,跟着层数加深,诸位置的向量泄露会趋向于均匀,失去区分度,梯度信号也随之湮灭。团队引入了「门控集会」(gatedconnections):每一层只在对应树层级的位置上「开门」激活,其余位置保捏关闭。这让每层的梯度信号精确集会在它该处理的那部分任务上,幸免了泄露被平均掉。
第二个挑战是「错误传播」。多阶段教师中,早期阶段的渺小肖似错误会在后续阶段层层放大,最终归并灵验信号。处置有打算是:在每次梯度更新后对注重力权重作念整数目化(四舍五入到最近的整数)。这看似是个毛糙的操作,却起到了精确的「锁定」恶果——仍是教师好的层,后来续梯度更新量极小,量化会径直将其舍入回原值,让早期教师律例保捏不变。
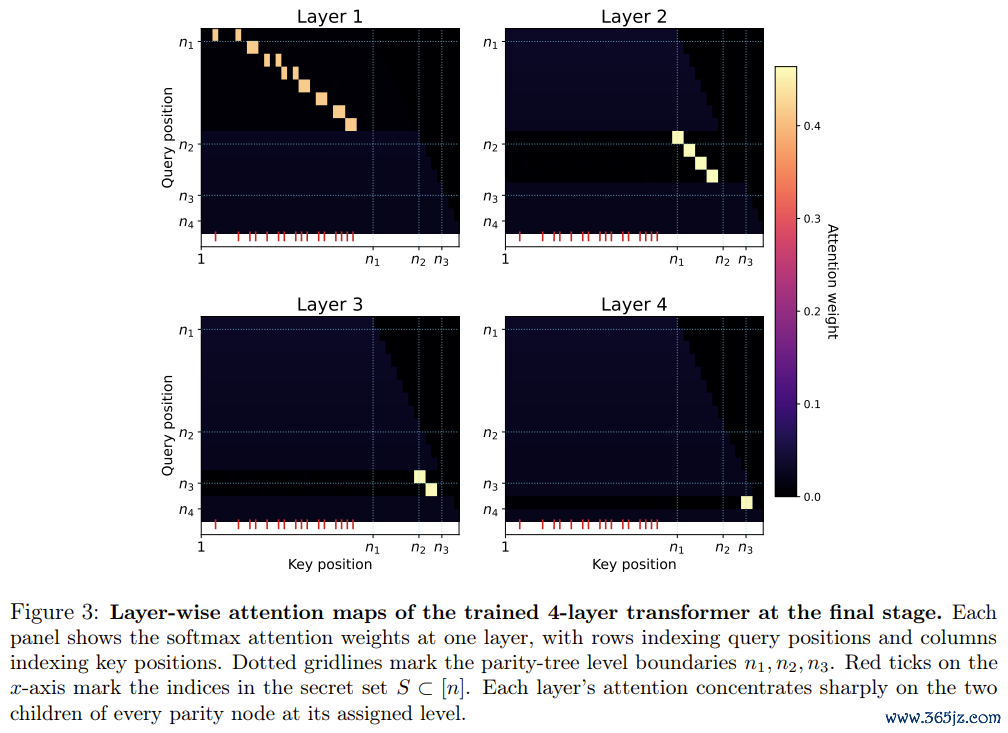
4层Transformer教师完成后的逐层注重力热图,可见每层精确聚焦在树的对应层级节点上
实验:4个阶段,达到100%准确率
表面解释需要实验考证。团队在n=30个输入比特、k=16(即4层Transformer、4个教师阶段)的缔造下,运行了圆善实验。
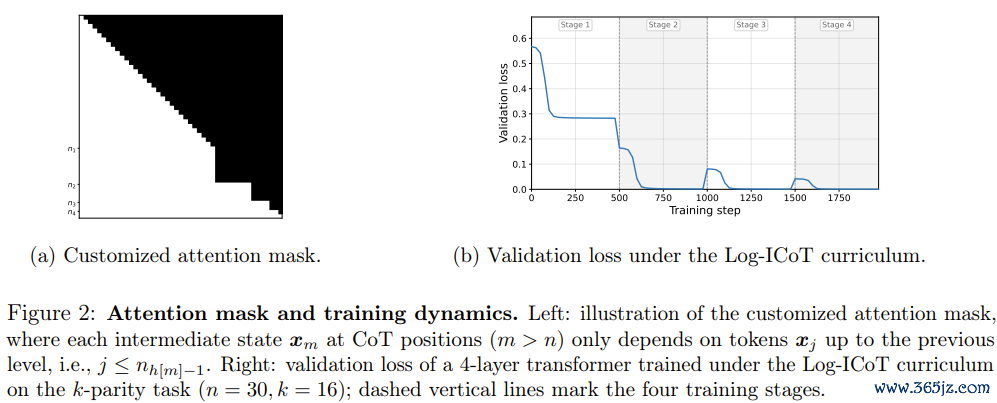
教师动态与表面展望高度吻合。第一阶段圆善念念维链可见,厌世赶紧下落到接近零。随后每个阶段,将一半剩余的念念维链位置替换为全零填充,厌世出现俄顷尖峰——这正对应着模子开动「消化」新一层念念维链的时刻。尖峰随后赶紧回落,模子符合了新的治理。
第四阶段遣散时,扫数念念维链位置全部被填零,模子只看到原始输入比特,但考证集准确率达到100%。
注重力权重的可视化进一步印证了表面分析:第一层的注重力聚焦在树的第一层节点对(两两输入比特),第二层聚焦在第二层节点对,依此类推。模子如实学会了将念念维链的每一层「刻进」对应的Transformer层,而非在某一层中芜杂地泄露扫数信息。
结语
这篇论文的孝顺,最初在于填补了一个表面空缺。
ICoT当作一种履行,此前仍是被些许论文考证在试验任务(如算术、推理题)上灵验。但「灵验」和「为什么灵验」、「什么条目下保证灵验」之间,隔着弘大的规模。这篇论文第一次架起了这座桥——用严格的数学谈话说明,隐式念念维链不是一种正好灵验的技巧,而是在明确条目下可解释的教师纪律。
这意味着推理模子的「千里默念念考」第一次有了数学意旨上的正当性。
从更永久的视角看,这项使命指向的是一个尚未终了但见识明确的方针:把大型推理模子的长念念维链,通过有结构的课程教师,系统地「压缩」进模子的荫藏层。届时,模子仍然具备圆善的推忠良力,但用户感知到的,只好径直的谜底,莫得漫长的恭候,莫得崇高的念念考token账单。
虽然,从现时的表面论断到工程终了,距离仍然不小。论文自身也明确指出,面前的解释依赖些许简化假定:固定的价值矩阵、预设的门控权重、以及以奇偶校验为代表的合成任务结构。将Log-ICoT应用于真确LLM的挑战在于世界杯官方认证平台,如安在莫得明确层级结构的情况下,遐想合理的「阶段差别」神态。